
Natural Language Processing and the Red List of Endangered Species
Description
Independent Project
October 19, 2017
Data for this project were obtained from a data mining program developed for a previous project. The code for the data mining can be viewed here.
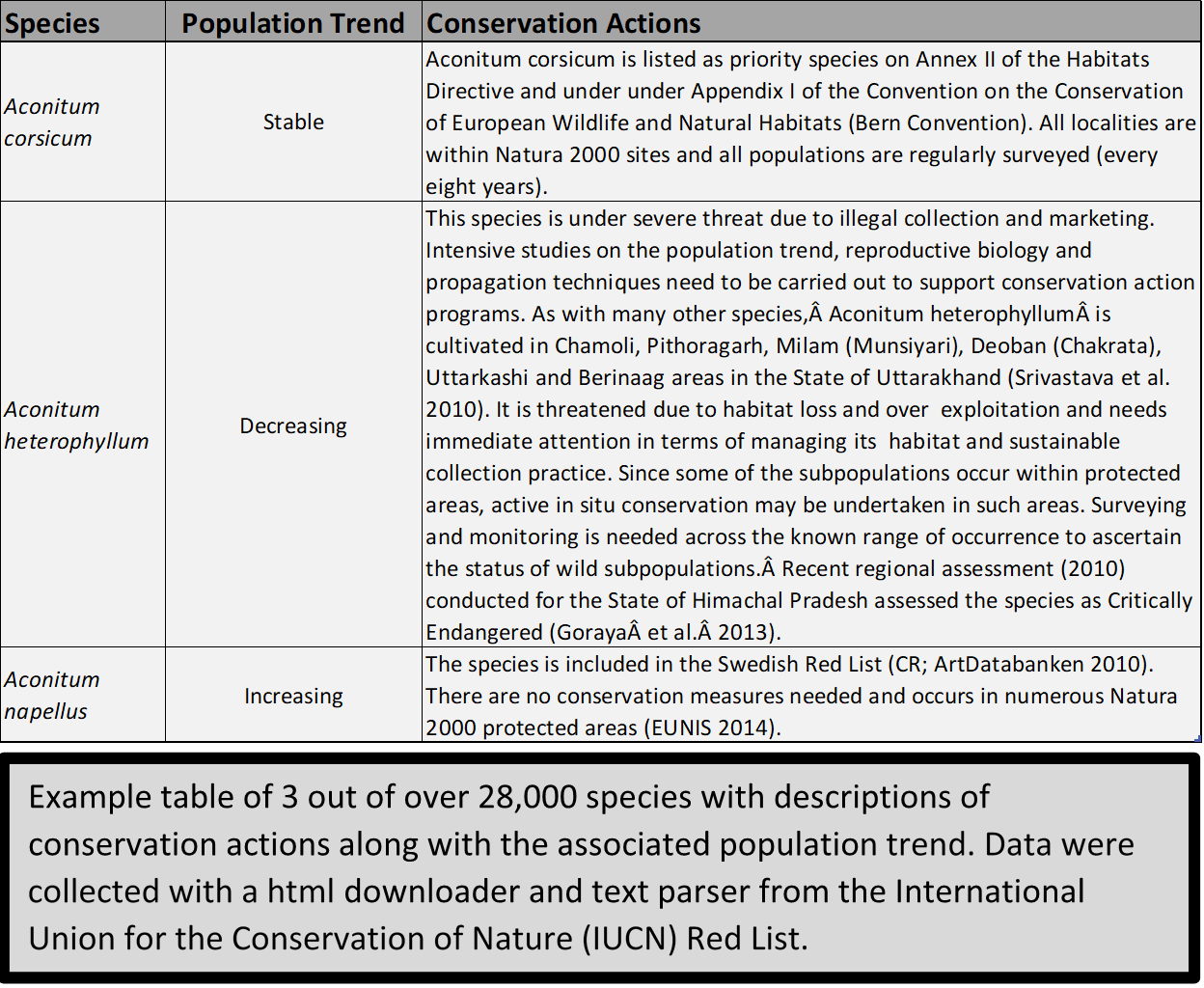
The goal of this project was to develop a machine learning algorithm to analyze text description of conservation actions in the International Union for the Conservation of Nature (IUCN) Red List of endangered species to predict the population trend of a given species based on the wording of the conservation actions.
The algorithm vectorizes each entry for conservation action using Count Vectorizer from the scikit package. These vectors are used to develop a model with 16,000 of the data points used as training data and the rest used for testing accuracy of the model. The model had about 60% accuracy as compared to a dummy model (most frequent population trend) with around 30% accuracy.
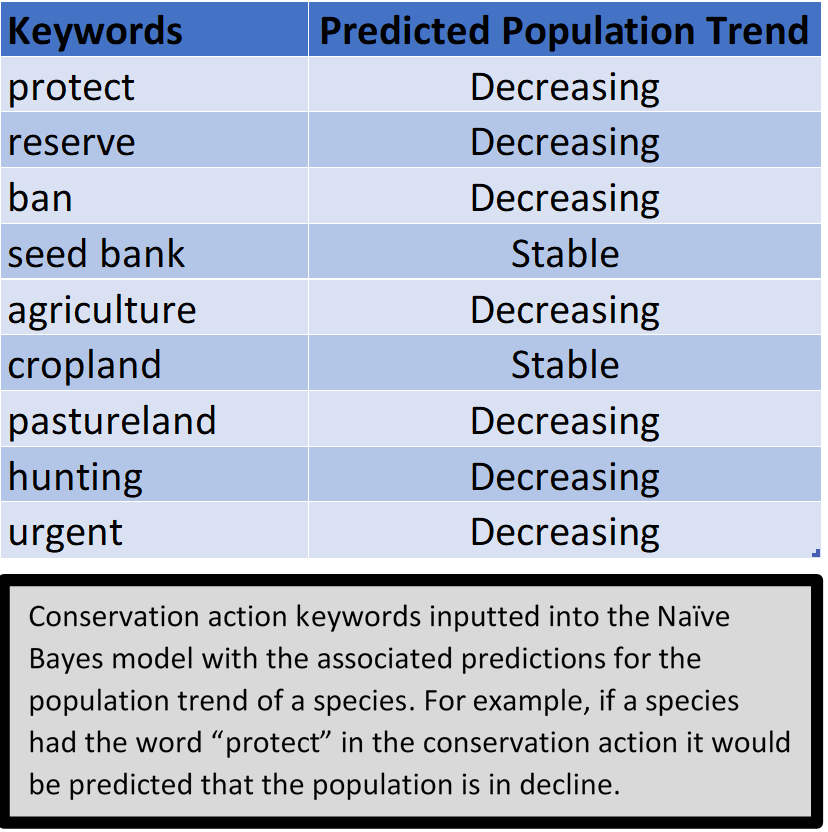
The keywords inputted had some interesting results (see table to the left). Although difficult to make conclusions without additional analysis, some possible interpretations are that for agriculture, pastureland is a more important factor than cropland in population decline. A counter-intuitive result was the "seed bank" keywords returning stable as seed banks are often used as a last resort conservation measure to protect against extinction.
IUCN 2017. IUCN Red List of Threatened Species. Version 2017-2 <www.iucnredlist.org>